
A Re-Introduction to C# References

Super happy to have won First Prize @ Codeproject for best article.
Reviewing what we need to know pre- and post- C# 7 features about the type system and references in particular, while correcting common misconceptions along the way.
Warm-up Exercise
What would the following code output? Hint: An array is a reference type.
private static void Main()
{
var intArray = new int[] { 10, 20 };
One(intArray);
Console.WriteLine(string.Join(", ", intArray));
intArray = new int[] { 10, 20 };
Two(intArray);
Console.WriteLine(string.Join(", ", intArray));
intArray = new int[] { 10, 20 };
Three(ref intArray);
Console.WriteLine(string.Join(", ", intArray));
}
private static void One(int[] intArray)
{
intArray[0] = 30;
}
private static void Two(int[] intArray)
{
intArray = new int[] { 40, 50 };
}
private static void Three(ref int[] intArray)
{
intArray = new int[] { 60, 70 };
}
C# Types: Reference, Value & Primitives
Put simply, a type is something that describes what a variable can hold.
Misconception: The new keyword means we are creating a reference type. Wrong! Perhaps this comes from the syntax provided by the primitive type aliases (and also many developers aren’t using structs regularly, so won’t be exposed to using new with them).
Primitive types are those, which the compiler supports directly, along with a range of operators and casting between them. They map to framework types e.g.
int maps to System.Int32
float maps to System.Single
The C# compiler will emit identical IL for the following lines.
System.int32 a = new System.int32();
int a = 0;</pre>
The latter is the alias, which primitives provide, that masks the use of the new keyword for those value types.
Below is a quick sketch of the types in C#. The Framework Class Library (FCL) obviously has a lot more that I won’t try to squeeze in.
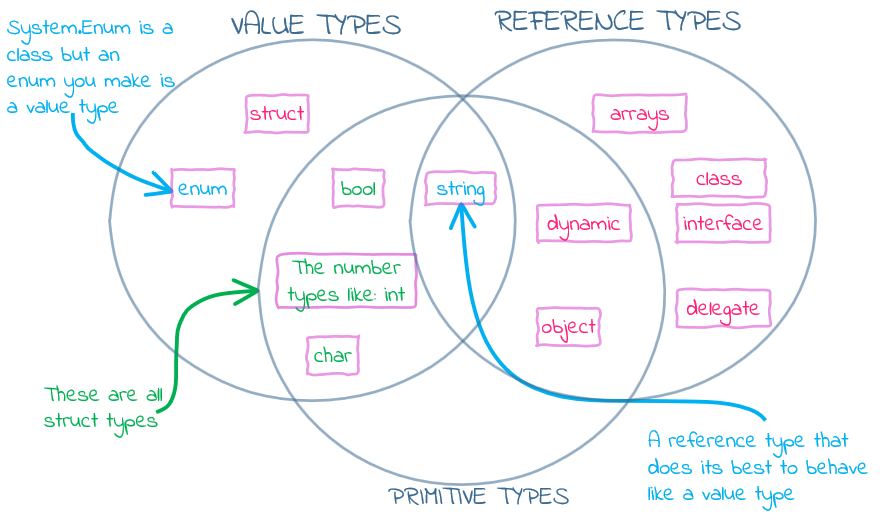
Value Types
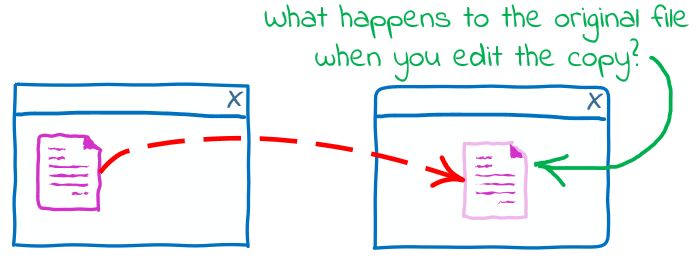
If you edit the copy made of a file, the changes do not affect the original file.
This is how value types are passed around in C# – as copies of the data. Given:
int originalInt = 0;
``
The **value** of `originalInt </span> is 0, which is the data we are intending to store in this variable.
When we pass `originalInt </span> as a value to a method (more on this later), or assign it to a new variable, we are making a copy. Any changes to the value in the copy, do not change the original e.g.
```chsarp
int originalInt = 0;
int copiedInt = originalInt;
// Output: original=0,copied=0
Console.WriteLine($"original={originalInt},copied={copiedInt}");
copiedInt += 500; // Add 500 onto the copied int
// Output: original=0,copied=500
Console.WriteLine($"original={originalInt},copied={copiedInt}");</pre>
500 was only added to the copy. <span class="lang:c# decode:true crayon-inline">originalInt</span> is still 0.
A note on inheritance
Just to confuse, all types, including System.ValueType, inherit from System.Object . Don’t get ideas – this is so we can have them behave like reference types through boxing. Us developers cannot actually inherit from value types in our code.
In summary
- The ‘value’ stored in a value type is the actual data.
- The default behaviour passing it around, is that we are making copies of this value.
- They support interfaces but there is no inheritance.
Reference Types
We’ll start this one with the analogy of a link to a file:

The ‘link’ from this analogy is a reference in C#.
A reference type still has a value – it’s just that the ‘value’ is a memory location where the actual data is.
By default, we are not directly working with that value. Whenever we access the variable, we are fetching the data stored in the memory location referenced by that value (Mads Torgersen uses the example for those from the pointer world - think of it as automatically dereferencing)
So, when you pass one of these around in code, it is making copies of this reference, not the data. Consider the following code:
var original = new SimpleObject() { Number = 100 };
var copied = original;
// Outputs: Original=100,Copied=100
Console.WriteLine($"Original={originalExample},Copied={copied}");
// Add 500 onto the Number property in the copied object reference
copied.Number += 500;
// Outputs: Original=600,Copied=600
Console.WriteLine($"Original={original},Copied={copied}");
We have created a new SimpleObject in memory and stored its memory address / location in the value of original.
When we make a copy of it, we are still copying the value as we do with value types:
var copied = original;
But the value being copied is this memory location.
So now copied and original both reference the same memory location. When we modify the data referenced by copied (the property inside it, Number), we are also changing original.

Now it gets interesting, and gets us a step closer to understanding the behaviour of the code in the warm-up exercise.
var original = new SimpleObject() { Number = 100 };
SimpleObject copied = original;
// Outputs: Original=100,Copied=100
Console.WriteLine($"Original={original.Number.ToString()}," +
$"Copied={copied.Number.ToString()}");
// This time, replace the original with a new object
original = new SimpleObject() { Number = 300 };
// Outputs: Original=300,Copied=100
Console.WriteLine($"Original={original.Number.ToString()}," +
$"Copied={copied.Number.ToString()}");
Remember – the ‘value’ stored in a reference type, is the reference to the object’s memory address. Now we create a another SimpleObject,_ after making a copy, and the new operator returns its memory address, which we store in `original</span> .
copied still points to the object that original used to point to. Confusing? Let’s return to our analogy:
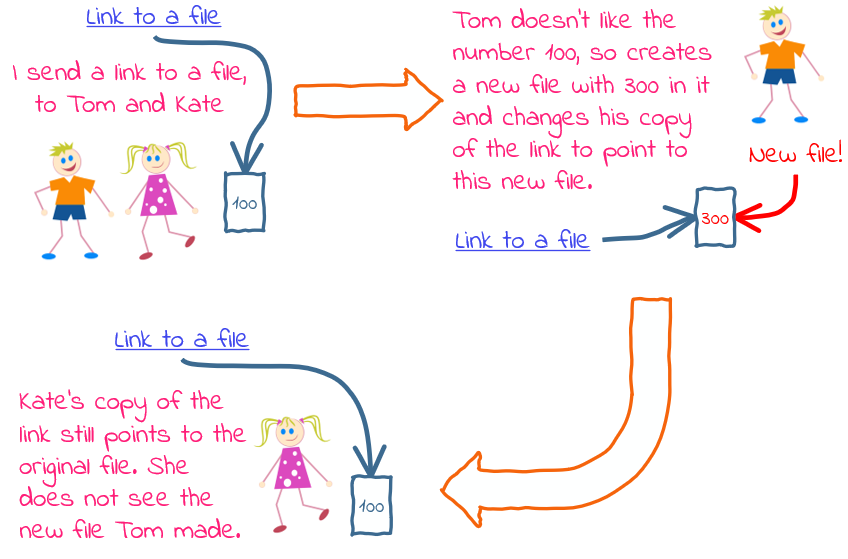
Tom has changed the copy of the link he has, which doesn’t affect Kate’s copy. So now their links point to different files.
In summary / need to know
- The ‘value’ in a reference type a memory location where the actual data is
- Whenever we access a reference type variable, we are fetching the data stored in the memory location it has as its value
- The default behaviour when we pass it around is that we are copying just this reference value. Changes to the data inside the object are visible by both the original and any copies. Changes to the actual memory location value are not shared between copies of that value.
Passing to a Method by Value
The default behaviour is passing by value without extra keywords looks like so:
private static void One(int[] intArray)
You’re probably doing this 99% of the time without a thought.
Nothing new to learn, so need for any code samples. This will exhibit all the behaviour already covered above:
- a value type will pass a copy of its value and changes to that copy won’t be seen by the caller
- a reference type will pass a reference to the object as its value and changes to the object will be seen by the caller; but if it is assigned to a brand-new object inside the method, the caller will not see this change
Passing to a Method by Reference
We have ref, out and with C# 7, in keywords for passing by reference.
Let’s just look at ref while we get our heads round what passing by reference means.
Note that the compiler will insist that the keyword appears in the call and the method, so our intention is clear both ends:
SomeMethod(ref myObjectInstance);
//…
private static void SomeMethod(ref MyObject myObjectInstance)
{
//…
Behaviour with Value types
If you pass a value type by reference, there is no copying and the called method is able to make changes to the data, which will be visible to the caller.
private static void ChangeNumb(ref int i)
{
i = 2;
}
static void Main(string[] args)
{
int i = 1;
ChangeNumb(ref i);
// Output: i = 2
Console.WriteLine($"i = {i.ToString()}");
}
Misconception: Passing a value type by reference causes boxing to occur. Wrong! Boxing occurs when you convert a value type to a reference type. Passing a value type by reference simply creates an alias, meaning we’d have two variables representing the same memory location.
Behaviour with Reference types
I was cheeky in the warm-up test - I passed a reference type, by reference, which is not a common thing to do.
Misconception: passing a reference type is the same as passing by reference. Wrong! This is easier to explain by trying to do both at the same time, and to observe how it differs from passing a reference type as a value.
Back to the file link analogy to look at what happens when we pass a reference type by reference to a method:
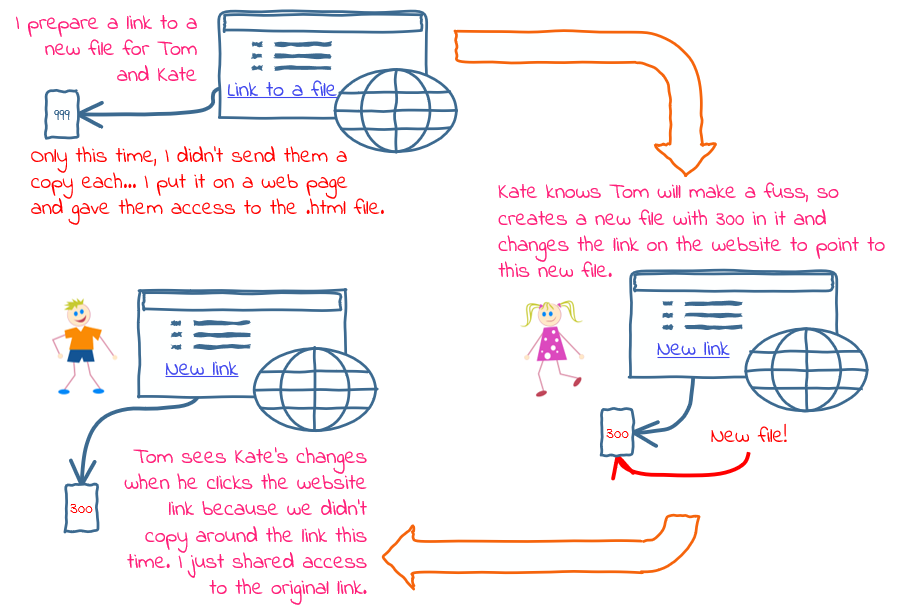
Instead of passing Tom and Kate copies of my link, I gave them access to the link itself. So as before, they both see changes to the file; but now also, if one of them changes the link to a new file, they both see that too.
So, using the ref keyword is kind of telling the compiler not to dereference / fetch the data from the memory location, but instead, pass the address itself, analogous to creating an alias.
We can see in the IL emitted for the code above, that the opcode stind is used to store the result back in the address of the int32 passed by address (note the &).
.method /*06000006*/ private hidebysig static void
ChangeNumb(/*08000004*/ int32& i) cil managed
{
// ...
IL_0006: stind.i4
// ...
}
In summary / need to know
- The
refmodifier allows a value to be passed in and modified – the caller sees the changes. - The ’value’ when used with reference types is the actual memory location hence it can change where the caller’s variable points in memory.
When Reference Types Meet Ref Locals
In C# 7 we got ref locals. They were introduced along side ref returns to support the push for more efficient, safe code.
I want to use them with reference types to give us a second chance to appreciate what happens when we pass a reference type around by reference.
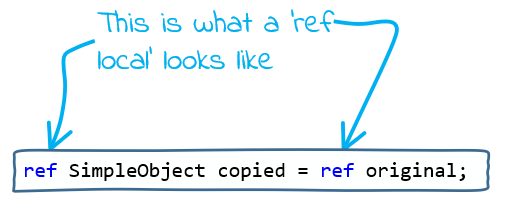
A complete code example:
var original = new SimpleObject() { Number = 100 };
ref SimpleObject copied = ref original;
// Outputs: Original=100,Copied=100
Console.WriteLine($"Original={original.Number.ToString()}," +
$"Copied={copied.Number.ToString()}");
// This time, replace the copied with a new object
copied = new SimpleObject() { Number = 300 };
// Outputs: Original=300,Copied=300
Console.WriteLine($"Original={original.Number.ToString()}," +
$"Copied={copied.Number.ToString()}");
Notice how the original is replaced by the copy now. In the IL we can see that ref locals utilise ldloca (for value and reference types) - we are copying the actual address where the value is (remember that the value in a reference type is a memory address were the object is).
SimpleObject copied = original;
// Emits the following IL:
ldloc.0 // Load value of local variable, original onto stack
stloc.2 // Pop the value we just put on the stack into copied
ref SimpleObject copied = ref original;
// Emits the following IL:
ldloca.s // Load the address of local variable, original onto the stack
stloc.1 // Pop the value we just put on the stack into copied
By using ref, we are essentially making an alias to this value containing the address – any changes to either, including pointing the reference to a new object, will affect both.
Ref returns
Just imagine I have an array of large structs and not the int I have used below.
I can now return a reference directly to an element in an int array without any copying.
private static ref int ElementAt(int[] array, int position)
{
return ref array[position];
}
static void Main(string[] args)
{
int[] intArray = { 2, 2, 2 };
ref int arrayElement = ref ElementAt(intArray, 2);
arrayElement = 4;
Console.WriteLine("[{0}]", string.Join(", ", intArray));
}
The gotcha with return ref is scope. Glance ahead and you’ll see I briefly cover the stack and stack frames, if you struggle with this bit. Ultimately, when a method returns you’ll lose anything on the stack and lose references to anything on the heap (and GC will claim it). With this in mind you can only ref return something visible in the scope of the caller. You can see above I am returning a reference to an index in the array held at the call site.
Ref locals & returns - useful for reference types?
The real value is to avoid copying around large value types – they complement the existing feature to pass by reference, adding the (missing) reference-like behaviour we already get with reference types.
We could start using ref returns and ref locals, but expect limited use cases if you work higher up the stack. Many libraries we use have already or will be utilising these and the new Span<T> work, so it is useful to understand how they play.
For reference types, as with passing to method by ref, you’re giving a caller access to the actual memory location and letting them change it. If anyone has come across some real-world scenarios please share so I can add it here.
Where do the Stack, Heap and Registers fit in all this?
Misconception: value types are always allocated on the stack. Wrong! If we’re going to get into discussions about where allocations occur, then it would be more correct to state that the intention is more like:
- short-lived objects to be allocated in registers or on the stack (which is going to be any time they are declared inside a method)
- and long-lived objects to be allocated on the heap.
EDIT: Eric Lippert suggests we should be thinking in terms of a ‘short term allocation pool and long term allocation pool … regardless of whether that variable contains an int or a reference to an object’.
Mostly, we shouldn’t be concerning ourselves with how any particular JIT allocates and we should make sure we know the differences in how the two types are passed around. That said, the .NET roadmap has been focused on ‘inefficiencies … directly tied to your monthly billing’, and delivered Span<T> and ref struct, which are stack-only.
For interest, here’s a few scenarios where we can expect a value type will to be heap allocated:
- Declared in a field of a class
- In an array
- Boxed
- Static
- Local in a yield return block
- Inside lambda / anon methods
What does it even mean to allocate on the stack (or the heap)?
This stack thing, it is actually that same call stack, made up of frames, which is responsible for the execution of your code. I’m not going to teach you about what a stack data structure is now.
A stack frame represents a method call, which includes any local variables. Those variables store the values for value or reference types we have already thoroughly discussed above.
A frame only exists during the lifetime of a method; so any variables in the frame also only exist until the method returns.
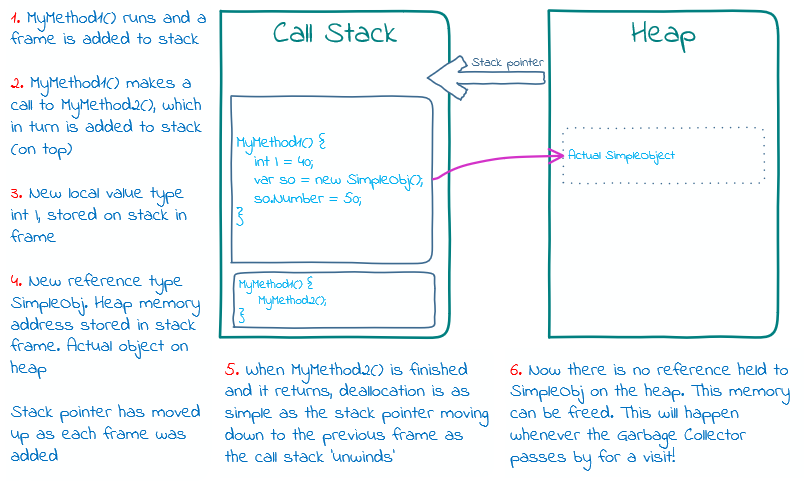
A big difference between stack and heap is that an object on the heap can live on after we exit the function, if there is a reference to it from elsewhere. So, given that passing references to objects around can potentially keep them alive forever, we can safely say that all reference types can be considered long-term and the objects/data will be allocated on the heap.
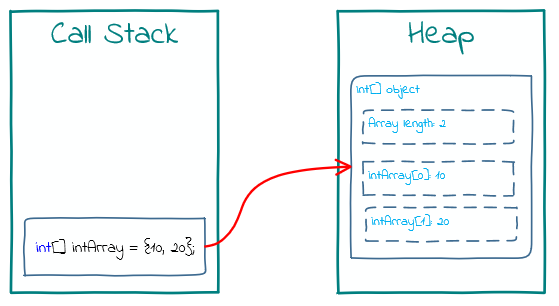
Misconception: The integers in an array of integers int[] will be allocated to the stack. Wrong. Value types are embedded in their container so they would be stored with the array on the heap.
Enforcing Immutability, Now That We’re Passing More References
Out and ref produce almost identical IL with the only difference being, the compiler enforces correct code who is responsible for initialising the object being referred to:
out– caller does not have to initialise the value. If they do it is discarded on calling the method. The called method must write to it.ref– caller must initialise the value
Great for avoiding copying value types but how do prevent the method being called from making unwanted modifications? C# 7 introduced the in modifier. It got the name by being the opposite of out (because it makes the reference (alias) read only; and the caller does have to initialise the value).
void DoWork(in BigStruct bigStruct)
{
//...
The equivalent for the other direction i.e. `return ref</span> , is the new modifier: ref readonly .
Here’s the immutable array example from the readonly ref proposal:
struct ImmutableArray<T>
{
private readonly T[] array;
public ref readonly T ItemRef(int i)
{
// returning a readonly reference to an array element
return ref this.array[i];
}
}
Now we can still get a reference to an array element without copying, but without the dangers of full access to the location:
ImmutableArray<int> immutableArray = new ImmutableArray<int>();
ref readonly int elementRef = ref immutableArray.ItemRef(2);
Briefly on Boxing
You can convert from value to reference type and back again. It can be implicit or explicit and is commonly seen when passing a value type to a method that takes object types:
{
int i = 4;
object o;
o = i; // implicit boxing
o = (object)i; // explicit boxing by casting
MyMethod(i);
}
// Implicit box
static void MyMethod(object o) {}
And unboxing:
int unboxedInt = (int) o;
An interesting case of implicit boxing is when working with structs that implement interfaces. Remember, an interface is a reference type.
Stuct Thing : IThing {
//...
IThing myThing = new Thing()
This will cause a boxing to occur.
Misconception: when a value type is boxed, changes to the boxed reference affect the value type itself. Wrong! You’d be thinking of when we create an alias with ref local or passing by reference. Changes to the boxed copy on the heap have no effect on the value type instance and vice versa.
When the C# compiler spots any implicit or explicit boxing it will emit specific IL:
IL_007c: box
When the JIT compiler sees this instruction, it will allocate heap storage and wrap the value type contents up in a ‘box’, which points to the object on the heap.
If you are careful, boxing is not going to hurt performance. Problems arise when they are occurring within iterations over large data sets. There is both additional CPU time for the boxing itself, followed by the additional pressure on the garbage collector.
Misconception: in the warm-up exercise, the array goes on the heap and so do the int objects in it. Therefore, the int objects have to be boxed. Wrong!
Remember we rebuffed the misconception that ALL value types go on the stack. With that mind, it doesn’t mean int objects ending up on the heap are boxed. Take the code:
int[] intArray = {10, 20};
If this were inside a method, a new array object would be allocated to the heap with a reference to it stored on the stack. The int objects 10 and 20 would be allocated to the heap also with the array.
Warm-up answer
30, 20
10, 20
60, 70
Summary
- The ‘value’ in a value type is the actual data.
- The default behaviour when we pass a value type around is that we are copying the actual value.
- The ‘value’ held in a reference type, is the reference to a location in memory where the data is.
- Whenever we access a reference type variable, we are fetching the data stored in the memory location it has as its value
- The default behaviour when we pass a reference type around is that we are copying just this reference value. Changes to the data inside the object are visible by both the original and any copies. Changes to the actual memory location value are not shared between copies of that value.
- The ref modifier allows a value to be passed in and modified – the caller sees the changes. The ‘value’ when used with reference types is the actual memory location, hence it can change where the caller’s variable points in memory.
- Amongst other things beyond article, C# 7 introduced a way to return by
ref. It also gave us thereadonlykeyword and in modifier to help enforce immutability.
Some homework because I ran out of space
- Doing reference and value type quality right
- When to use structs vs classes
- How string differs
- Extension method refs
- Readonly structs
- Nullable value types and look forward to nullable reference types
Sources
Who knows? I play with the internals a lot and read a great deal, so can’t be sure where it all comes from. It’s just in my head now. Probably:
- Any of the Mads or Skeet talks I’ve watched
- The writings of by Eric Lippert
- Writing High Performance .NET Code by Ben Watson
- CLR Via C# by Jeffrey Richter
- Pro .NET Performance by Sasha Goldshetin
- Probably loads from MS blogs and MS repositories at github.com
Comments